近日,由光明实验室马飞研究员作为通讯作者主导的三篇数字人方向研究成果,分别被人工智能顶刊IEEE Transactions on Pattern Analysis and Machine Intelligence(TPAMI,影响因子:18.6)及顶会ACM MM、IJCAI等录用。
Human Motion Video Generation: A Survey
与清华大学合作的综述论文(作者:Haiwei Xue, Xiangyang Luo, Zhanghao Hu, Xin Zhang, Xunzhi Xiang, Yuqin, Dai, Jianzhuang Liu, Zhensong Zhang, Minglei Li, Jian Yang, Fei Ma, Zhiyong Wu, Changpeng Yang, Zonghong Dai, Fei Yu) 被人工智能顶刊TPAMI接收。
论文核心聚焦2D数字人视频动作生成任务,总结梳理超过200多篇相关文献,将完整视频数字人生成完整流程划分为五大关键阶段(输入处理、运动规划、动作视频生成、细节精修和输出),同时按驱动源分为视觉、文本、音频驱动三类分别探讨数字人视频生成任务的方法框架,首次讨论了大语言模型(LLMs)在动作规划中的潜力,为科研社区提供了完善的技术路线和方法框架整理。
在技术层面,论文全面梳理了超过200篇相关文献,系统分析了三大主流驱动模态下的生成方法。在视觉驱动方面,涵盖了肖像动画、舞蹈视频生成、虚拟试衣等应用;在文本驱动方面,探讨了从文本到面部表情(Text2Face)和从文本到全身动作(Text2MotionVideo)的生成技术;在音频驱动方面,详细分析了口型同步、头部姿态驱动、全身动作生成等任务。论文特别关注了近年来扩散模型(Diffusion Models)在该领域的突破性进展,深入剖析了不同的网络架构设计,包括纯噪声输入、参考图像输入、引导条件输入等多种生成框架,以及空间注意力、交叉注意力、时序注意力等关键机制的组合方式。此外,论文整理的64个公开数据集资源和建立的评估基准,将极大促进该领域的研究规范化。
Github Repo:https://github.com/Winn1y/Awesome-Human-Motion-Video-Generation
OnlineHOI: Towards Online Human-Object Interaction Generation and Perception
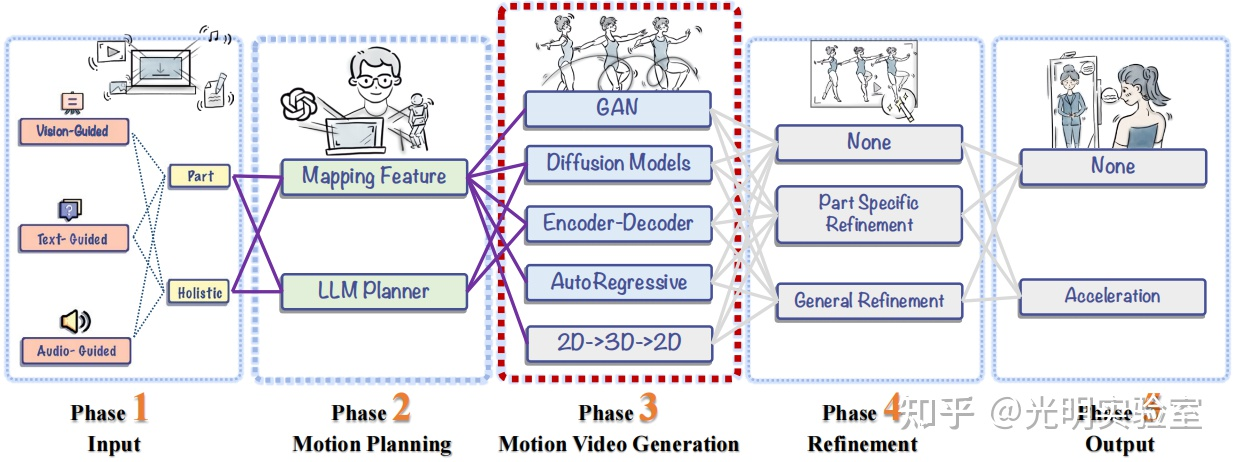
该论文(作者:Yihong Ji, Yunze Liu, Yiyao Zhuo, Weijiang Yu, Fei Ma, Joshua Zhexue Huang, Fei Yu)被CCF A类会议ACM MM2025接收。论文提出了OnlineHOI框架,首次将人-物交互(HOI)的感知和生成任务从传统的离线设置扩展到在线设置。在线设置更贴近现实场景,网络只能访问历史帧信息而无法预知未来,这给现有方法带来了巨大挑战。论文的核心创新在于采用Mamba架构替代Transformer,并结合记忆增强机制。Mamba模型通过状态空间模型和高效的递归结构,在处理流式数据时具有天然优势,特别适合在线场景下的连续状态更新。研究团队设计了短期记忆和长期记忆两种记忆模块,短期记忆采用滑动窗口机制存储最近的帧信息,长期记忆则通过相似度计算筛选保留关键历史信息,两者融合形成增强记忆。在生成任务中,OnlineHOI-G使用基于Mamba的扩散模型,根据演员的动作和物体几何信息生成反应者的动作。在感知任务中,OnlineHOI-P处理4D点云视频流,实时预测当前时刻的交互动作类别。
VideoHumanMIB: Unlocking Appearance Decoupling for Video Human Motion In-betweening
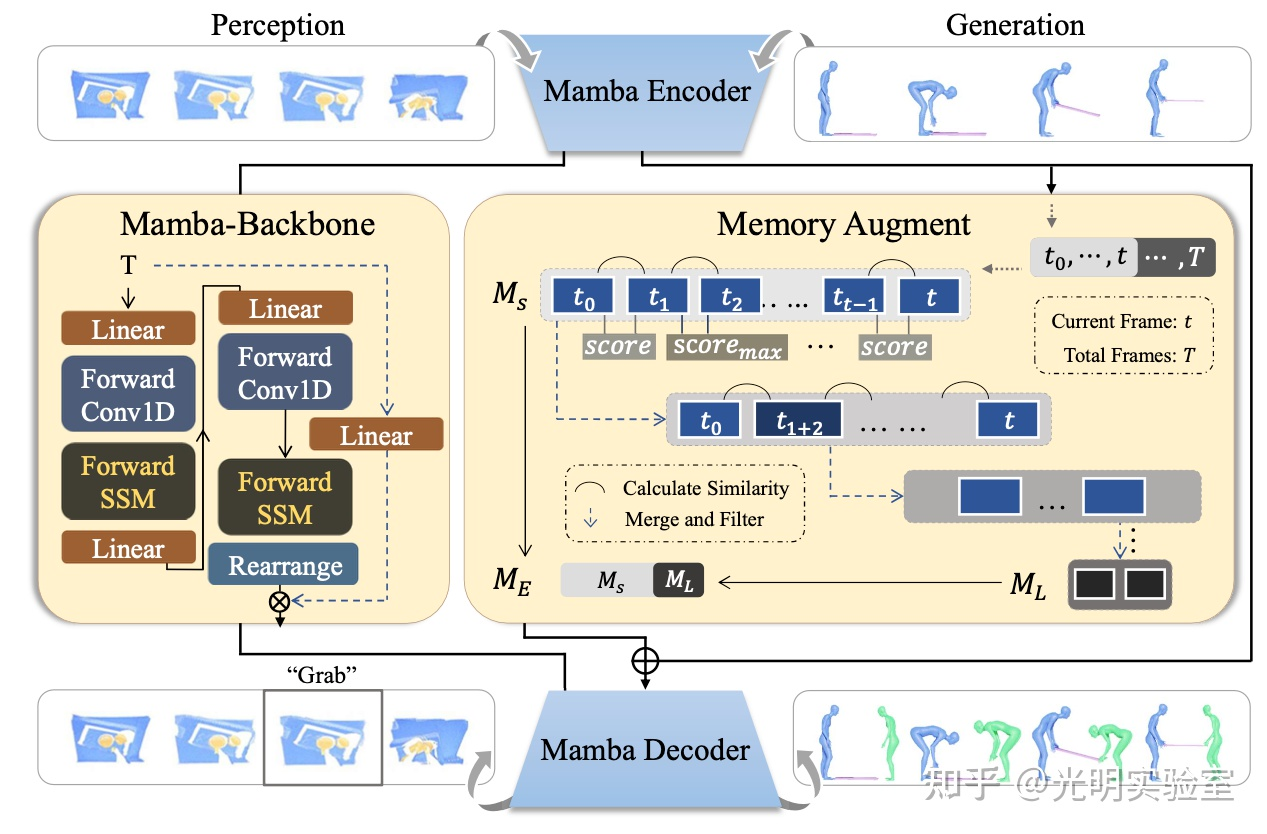
该论文(作者:Haiwei Xue, Zhensong Zhang, Minglei Li, Zonghong Dai, Fei Ma, Fei Yu, Zhiyong Wu) 被CCF A类会议IJCAI 2025接收。论文提出了VideoHumanMIB,一个专门用于视频人体动作插帧(Video Human Motion In-betweening)的新型框架,旨在解决数字人视频生成中不同动作片段之间的自然过渡问题。与传统的视频插帧方法主要用于提升帧率不同,该研究聚焦于在两个差异较大的人体动作之间生成流畅、自然的过渡序列。论文采用两阶段训练框架:第一阶段设计了外观重建自编码器,将视频中的外观信息和运动信息进行解耦,提取鲁棒的外观不变特征;第二阶段开发了增强的扩散模型,同时利用运动光流和人体姿态作为引导条件,在学习的潜在空间而非像素空间进行操作,更好地捕捉底层运动动态。框架通过双帧约束损失和运动流损失进行优化,确保时序一致性和自然的动作过渡。
其他数字人研究成果还包括Audio-Driven Talking Face Video Generation with Joint Uncertainty Learning(ACM ICMR 2025)、GaussianPU: A Hybrid 2D-3D Upsampling Framework for Enhancing Color Point Clouds via 3D Gaussian Splatting(IROS)、UniSync: A Unified Framework for Audio-Visual Synchronization(IEEE ICME 2025)、MuseFace: Text-driven Face Editing via Diffusion-based Mask Generation Approach(IEEE ICME 2025)等。
以上成果展现了光明实验室媒体智能团队在数字人方向的持续创新。未来,该团队将进一步与数字人及交互生成、多模态大模型等作为载体,与情感智能更加深入结合研究。也欢迎对该方向感兴趣的老师与同学,联系与交流:mafei@gml.ac.cn。



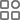





 发布时间:2025-07-31
发布时间:2025-07-31 作者:光明实验室
作者:光明实验室 浏览:1469次
浏览:1469次