


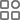
光明实验室大数据智能处理与分析团队三篇论文被人工智能领域顶级国际会议接收
![]() 发布时间:2025-10-14
发布时间:2025-10-14![]() 作者:光明实验室
作者:光明实验室![]() 浏览:623次
浏览:623次

01
Privacy-Shielded Image Compression: Defending Against Exploitation from Vision-Language Pretrained Models (ICML2025)
作者:
Xuelin Shen, Jiayin Xu, Kangsheng Yin, Wenhan Yang
内容简介
随着视觉语言预训练 (VLP) 模型语义理解能力的提升,保护公开发布的图像免遭搜索引擎和其他类似工具的利用变得越来越困难。在此背景下,本工作旨在通过在图像压缩阶段实施防御措施来保护用户隐私,防止其被利用。具体而言,我们提出了一种灵活的编码方法,称为隐私保护图像压缩 (PSIC),它可以生成具有多种解码选项的比特流。默认情况下,比特流会被解码以保持令人满意的感知质量,同时防止被 VLP 模型解读。我们的方法还保留了原始图像压缩功能。通过可自定义的输入条件,所提出的方案可以重建保留其完整语义信息的图像。我们提出了一个条件潜在触发生成 (CLTG) 模块,用于根据可定制的条件生成偏差信息,从而将解码过程引导至不同的重构版本。此外,还设计了一个面向不确定性感知加密 (UAEO) 的优化函数,用于利用目标 VLP 模型对训练数据的不确定性推断出的软标签。本工作进一步融入了一种自适应多目标优化策略,旨在通过统一的训练流程同时提升加密性能和感知质量。提出的方案即插即用,可无缝集成到大多数现有的学习图像压缩 (LIC) 模型中。在多个下游任务上进行的实验证明了我们设计的有效性。

实验结果
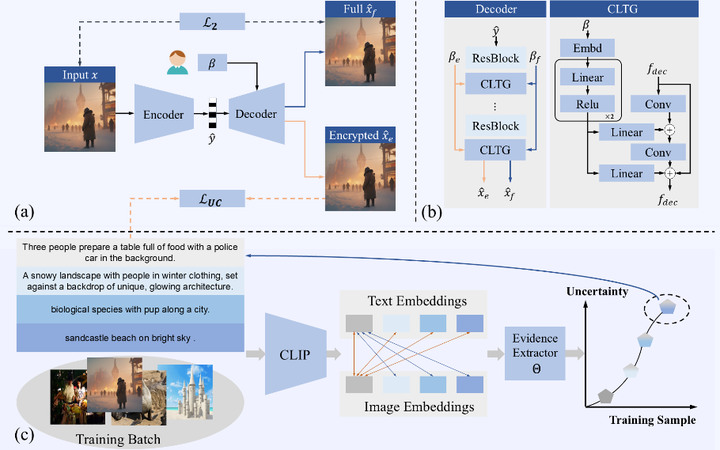
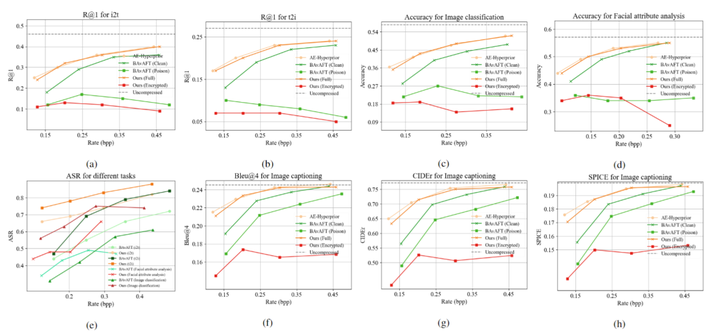
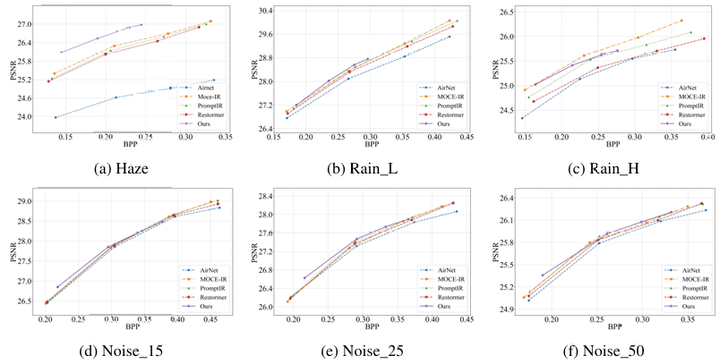
本方法在图文检索、图像分类、图像字幕和人脸属性分析四个下游任务上验证了优越性。如图 3 所示,相较 BAvAFT方法,PSIC 在加密(攻击)效率上呈现压倒性优势,ASR 平均提升 12.9%, encrypted 版本显著误导 CLIP,而 full 版本仍完整保留语义。感知质量方面,图 4 表明 PSIC-full 与主干LIC 的 rate–perception 曲线保持一致,并与BAvAFT-clean相比,PSIC在四个 bpp 点上平均提升 1.0 dB;而 encrypted 版本同样保持良好的感知质量,能够满足常规的感知需求。更关键的是,BAvAFT 需对 clean、poison 模式分别编码,PSIC 则一次压缩即可同步生成两种语义表示。图 5 提供了可视化示例。

工作贡献
✦ 我们提出了一种灵活的图像压缩网络,该网络可以通过控制下游 VLP 模型是否允许访问图像来适应用户需求,同时保持良好的感知质量。
✦ 提出了一个条件潜在触发生成 (CLTG) 模块和一个自适应多目标优化策略,使单个比特流能够解码为两个具有互斥目标的版本。
✦ 引入了一个不确定性感知加密导向 (UAEO) 优化函数,用于检查目标模型先验知识中的不确定性,从而增强鲁棒性并提高误导目标 VLP 模型的成功率。
02
Prompt-Guided Alignment with Information Bottleneck Makes Image Compression Also a Restorer (NeurIPS2025)
作者:
Xuelin Shen, Quan Liu, Jiayin Xu, Wenhan Yang
内容简介
随着学习式图像压缩 (LIC) 模型在理想条件下的性能日益强大,其在真实世界复杂场景中的应用却变得愈发困难。图像在采集过程中常会受到雾、雨、噪声等多种环境因素的干扰而产生“退化”。由于这些退化图像与模型训练时所用的“干净”图像存在分布上的巨大差异,直接压缩会导致效率急剧下降,而为每一种退化类型都重新训练一个专用模型在成本和实践上都不可行。在此背景下,本工作旨在通过在编码阶段实施自适应调整来提升对退化图像的压缩效率。具体而言,我们提出了一种名为“信息瓶颈约束的潜在表示统一 (IB-LRU)”的方案,它通过一个轻量级的编码器端插件模块,在不修改压缩模型主干的前提下,实现了压缩与修复的统一框架。我们提出了一个概率性提示生成器 (PPG) 模块,用于根据不同的退化类型动态生成指导信息,即“提示 (prompt)”。为了使该“提示”信息只专注于退化本身的特征,而非图像的冗余上下文内容,本工作进一步融入了信息瓶颈 (IB) 原理进行约束。最终,这些被约束的提示信息通过一个门控调制过程来引导编码器,旨在将退化图像的潜在表示与干净图像的进行对齐,从而提升熵模型的准确性与压缩效率。提出的方案即插即用,可无缝集成到大多数现有的学习式图像压缩 (LIC) 模型中。在多种LIC主干和多种退化场景下进行的大量实验证明了我们设计的有效性。
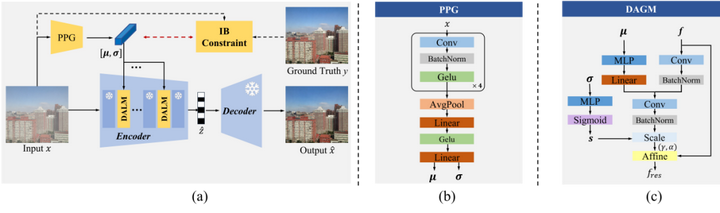
实验结果
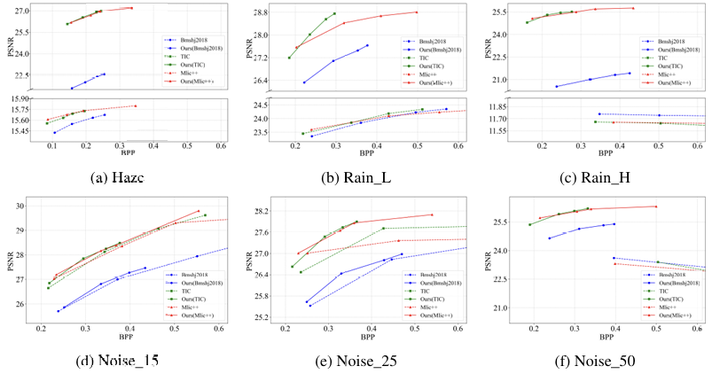
本方法在多种图像退化场景下验证了其有效性。如图 2 所示,相较于原始压缩模型,IB-LRU 在码率性能上呈现显著优势,在小雨、大雨及高强度噪声场景下,bpp 平均分别降低 27.1%、51.6% 和 64.9%,同时感知质量也获得明显提升。码率-感知性能方面,图 3 表明相较于“先修复后压缩”的级联范式,IB-LRU 在实现具有竞争力的感知质量的同时,展现出总体性的码率优势,实现了更优的码率-感知权衡。更关键的是,IB-LRU 方案在额外参数量和推理速度上远优于级联方法,展现了巨大的实际应用潜力。图 4 提供了可视化示例。

工作贡献
✦据我们所知,提出的IB-LRU是第一个旨在通过轻量级的即插即用设计来提高LIC模型在各种退化场景下的有效性的探索。
✦ 我们提出了一种新颖的概率提示学习策略,该策略使用一组分布参数(而不是向量)来表征每种退化类型,从而产生更具判别性的退化表示。
✦ 我们为概率提示学习过程引入了一种基于信息瓶颈(IB)的优化准则,并推导出一个变分近似界限,来指导我们的优化策略设计。
03
End-to-End Low-Light Enhancement for Object Detection with Learned Metadata from RAWs (NeurIPS2025)
作者:
Xuelin Shen, Haifeng Jiao, Yitong Wang, Yulin He, Wenhan Yang
内容简介
虽然 RAW 图像通过避免图像信号处理(ISP)带来的失真并在低照度条件下保留更多信息,相较于 sRGB 图像具有优势,但其广泛应用仍受限于高存储成本、高传输负担以及对下游任务架构的重大修改需求。为了解决这些问题,本文提出了一种新的基于原始图像的机器视觉范式,称为 紧凑型 RAW 元数据引导的图像精炼(CRM-IR)。具体而言,我们设计了一个 面向机器视觉的图像精炼模块(MV-IR),该模块利用学习到的 RAW 元数据对 sRGB 图像进行优化,使其更符合机器视觉特征。同时,我们提出了一种 跨模态上下文熵(CMCE) 网络,用于 RAW 元数据的提取与压缩。该网络建立在学习型图像压缩的潜在表示与熵建模框架之上,充分利用 RAW 图像与对应 sRGB 图像之间的上下文关联,从而实现更高效、更紧凑的元数据表示。此外,我们还结合了来自 ISP 管线的先验信息,以简化精炼过程并实现更高的效率。这种设计使 CRM-IR 能够专注于从 RAW 图像中提取最关键的元数据,以支持下游的机器视觉任务,同时保持即插即用的特性,完全兼容现有的成像管线,无需修改模型架构或 ISP 模块。我们在多种目标检测网络上实现了 CRM-IR 框架,大量低照度实验结果表明,该方法能在额外码率低于 10⁻³ bits per pixel 的情况下显著提升检测性能。

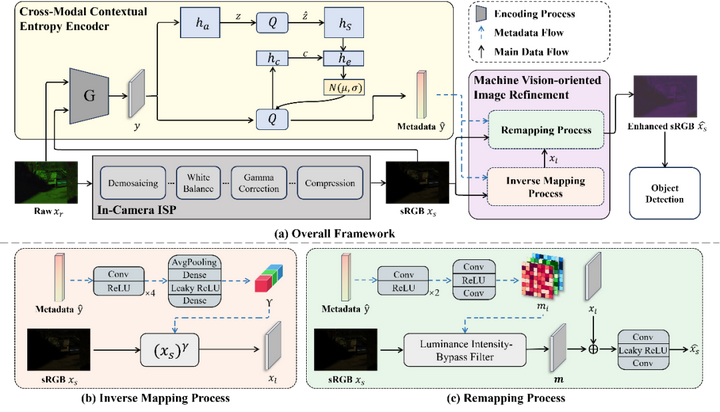
数据集RID
为了推进基于 RAW 的机器视觉技术的发展,我们构建了“暗环境下的 RAW 数据集”(RID)——这是一个多样且规模庞大的数据集,包含了 500 组经过标注的 RAW-sRGB 对,这些数据是在 8 个物体类别下的真实低光场景中拍摄的。RID 满足了现有开源数据集中的关键空白,并为通过跨数据集验证来评估基于 RAW 的物体检测的泛化能力提供了强有力的基准。部分图像示例如图 3 所示。

实验结果
本工作在目标检测任务上验证了所提出方法的优越性。如表所示,相较于基线模型 YOLOv3、Faster R-CNN 和 CenterNet,本方法在仅引入低于 0.5% 的原始元数据开销下,平均分别实现了 2.14%、1.79% 和 1.64% 的 mAP 提升。在与基于 sRGB 的最新方法 Zero-DCE、KinD 和 YOLA 的对比中,本方法平均提升约 0.94%、1.60% 和 0.96%,充分证明利用原始图像信息能够有效克服传统 ISP 处理的局限。相比基于原始图像的 RAOD 方法,本方法在保持相当性能的同时,仅需传输紧凑元数据流,显著降低了存储与传输成本。跨数据集实验进一步验证了其强泛化能力,在未见场景下仍能维持稳定的检测精度。关于 YOLOv3、Faster R-CNN 和 CenterNet 三个基线模型的定量评估结果,分别列于表1,2和3 中。图 3 提供了可视化示例。
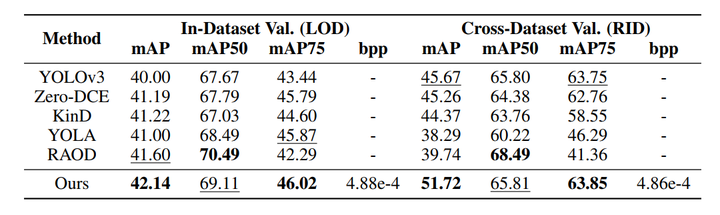
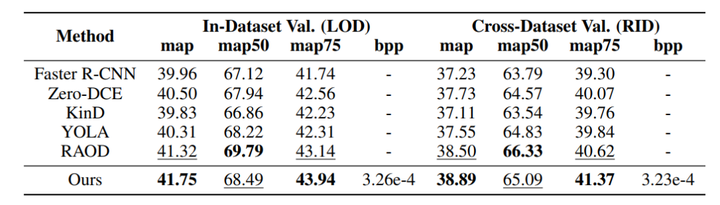


工作贡献
✦我们提出了一种基于原始图像的新型机器视觉模式,该模式仅从原始图像中提取出最核心的信息,以指导基于机器的 sRGB 图像优化。这种设计能够无缝地作为插件集成到现有的基于 sRGB 的视觉流程中,同时保持极低的存储和传输开销。
✦ 我们引入了一种新颖的原始元数据编码器,它能够充分利用处理后的 sRGB 图像与原始图像之间的跨模态上下文信息。这使得所提出的方案能够仅传输极少量的原始元数据,同时显著提升后续性能。
✦ 为了推进基于 RAW 的机器视觉技术的发展,我们构建了“暗环境下的 RAW 数据集”(RID)——这是一个多样且规模庞大的数据集,包含了 500 组经过标注的 RAW-sRGB 对,这些数据是在 8 个物体类别下的真实低光场景中拍摄的。RID 满足了现有开源数据集中的关键空白,并为通过跨数据集验证来评估基于 RAW 的物体检测的泛化能力提供了强有力的基准。



 发布时间:2025-10-14
发布时间:2025-10-14 作者:光明实验室
作者:光明实验室 浏览:623次
浏览:623次