OddGridBench:首个可控的细粒度视觉差异识别评测基准
![]() 发布时间:2026-03-16
发布时间:2026-03-16![]() 作者:光明实验室
作者:光明实验室![]() 浏览:218次
浏览:218次

近日,光明实验室生成式大模型团队的论文 “OddGridBench: Exposing the Lack of Fine-Grained Visual Discrepancy Sensitivity in Multimodal Large Language Models”成功被人工智能领域顶级会议 CVPR 2026 正式接收。该研究由光明实验室和深圳大学联合培养博士生翁腾缙,在姜文浩研究员与明仲教授的共同指导下完成。
OddGridBench: Exposing the Lack of Fine-Grained Visual Discrepancy Sensitivity in Multimodal Large Language Models
Tengjin Weng,Wenhao Jiang,Jingyi Wang,Ming Li,Lin Ma,Zhong Ming
主要内容
本论文提出了 OddGridBench,用于系统评估多模态大语言模型的细粒度视觉差异感知能力,并进一步提出 OddGrid-GRPO 强化学习框架以提升模型的差异辨别能力。实验结果表明,当前先进多模态模型在该任务上仍明显落后于人类,该工作为多模态模型感知能力研究提供了新的评测工具与研究方向。
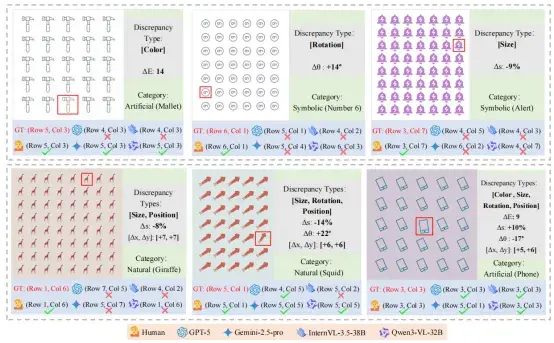
OddGridBench,一个专注于评估多模态大语言模型细粒度视觉差异感知能力的系统性评测基准。该基准(如图1所示)通过构建由大量视觉元素组成的网格场景,在颜色、大小、旋转和位置等视觉属性上引入细微差异,并要求模型识别其中与其他元素不同的目标,从而系统评估模型在细粒度视觉感知任务中的能力。
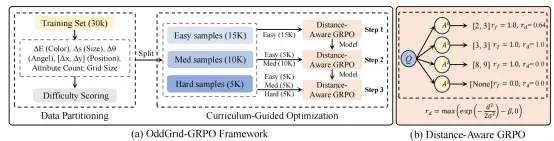
在此基础上,进一步提出 OddGrid-GRPO 强化学习训练框架,通过课程学习与距离感知奖励机制,引导模型逐步学习细粒度视觉差异的识别能力。所提出的方法能够显著提升模型的视觉辨别能力。
OddGridBench 的提出为多模态大模型研究提供了新的评测视角与工具,首次系统性聚焦于视觉差异感知这一基础感知能力,为理解模型在视觉理解与空间推理中的真实能力提供了重要依据,也为未来多模态模型感知能力的提升和评测方法的发展奠定了基础。
核心创新点
构建细粒度视觉差异评测基准
OddGridBench 构建了一个专门用于评估多模态大语言模型细粒度视觉差异感知能力的评测基准。该基准通过网格化视觉场景系统控制颜色、大小、旋转和位置等低层视觉属性,使模型需要在高度相似的视觉元素中识别细微差异,从而系统评估模型的基础视觉感知能力。
提出 OddGrid-GRPO 强化学习优化框架
论文进一步提出 OddGrid-GRPO 方法,通过结合课程学习与距离感知奖励机制,逐步提升模型对细粒度视觉差异的识别能力。该方法能够提供连续的空间反馈信号,从而有效提升模型在视觉定位与差异识别任务中的表现。
系统评估主流多模态大模型能力
研究对包括 Qwen-VL、InternVL、Gemini、GPT 等在内的多种主流多模态模型进行了系统评测。实验结果表明,即便是当前最先进的模型,在细粒度视觉差异检测任务上仍明显落后于人类水平,揭示了多模态模型在基础视觉感知能力方面的重要瓶颈。
跨数据集与真实场景的泛化能力
研究进一步在真实图像异常检测数据集 MVTec-AD 和 VisA 上进行了扩展评测,并引入 MNIST 和 SCC(Similar Chinese Characters) 两个结构化字符数据集开展跨数据集测试。实验结果表明,所提出的 OddGrid-GRPO 在多个数据集上均稳定优于基线方法,说明模型不仅能够适应合成图标场景,还能够有效迁移到真实工业异常检测和相似字符辨别等任务中,展现出良好的跨场景泛化能力。
OddGridBench 的提出不仅为多模态大模型研究提供了新的评测视角,也为理解模型视觉感知能力、提升多模态推理水平以及推动其在真实异常检测、工业质检等实际场景中的应用提供了重要基础。
实验结果
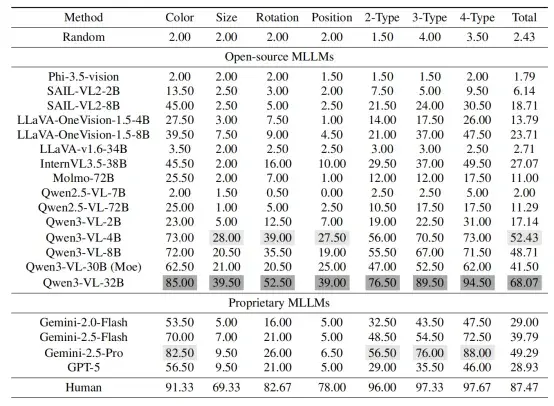
评测结果表明,即使是当前最先进的多模态大模型,在 OddGridBench 上的整体表现仍明显落后于人类。在所有评测模型中,表现最好的 Qwen3-VL-32B 总体准确率为 68.07%,而 Gemini-2.5-Pro 为 49.29%,GPT-5 为 28.93%,均显著低于人类 87.47% 的平均准确率。
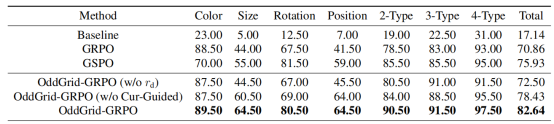
在此基础上,论文提出的 OddGrid-GRPO 方法显著提升了模型的细粒度视觉差异识别能力。实验结果显示,相比于Baseline(17.14%),采用标准 GRPO 训练后准确率提升至 70.86%,而进一步引入课程学习和距离感知奖励机制的 OddGrid-GRPO 则将整体准确率提升至 82.64%。这些结果表明,OddGrid-GRPO 能够有效增强模型对细粒度视觉差异的感知能力,并显著提升多模态模型在复杂视觉场景中的表现。
进一步的泛化实验表明,所提出的 OddGrid-GRPO 不仅在原始基准上有效,在跨数据集和跨输入形式设置下同样表现出稳定优势。在 MVTec-AD、VisA、MNIST 和 SCC 等外部数据集上,OddGrid-GRPO 均优于基线模型和标准 GRPO;同时,在非网格输入形式下,模型接收多张独立图像时依然能够保持较强的异常识别能力。
未来计划
当前的评测结果表明,多模态大语言模型在细粒度视觉差异感知能力方面仍然存在明显不足,尤其在旋转、位置等空间属性变化以及多属性组合差异任务中表现较弱。这表明,在推动模型具备更加接近人类的视觉感知与空间理解能力方面,仍需要进一步开展系统性的基础研究与方法创新。作为首个专注于评估 MLLMs 细粒度视觉差异感知能力的系统性评测基准,OddGridBench 为研究者提供了新的研究工具和分析视角。未来工作将进一步扩展数据规模与任务类型,并探索更加有效的训练策略,以持续提升模型在复杂视觉场景中的感知能力。同时,团队也计划将相关方法拓展到真实异常检测、工业质检等实际应用场景,推动多模态模型从“能看图”向“能理解细粒度视觉差异”的方向发展。
目前光明实验室生成式大模型团队正在招聘大模型算法研究员、工程师和实习生,欢迎对多模态大模型研究感兴趣的同学加入。有意向者可将简历发送至 jiangwenhao@gml.ac.cn。
论文链接:
https://arxiv.org/abs/2603.09326v1
END
素 材 丨生成式大模型团队
编 辑 丨 李沛昱 曾小告
责 编 丨 陈贞儒
欢迎投稿、建议:gmlab@gml.ac.cn



 发布时间:2026-03-16
发布时间:2026-03-16 作者:光明实验室
作者:光明实验室 浏览:218次
浏览:218次