光明实验室构建大规模对话理解基准MindDialog
![]() 发布时间:2026-05-07
发布时间:2026-05-07![]() 作者:光明实验室
作者:光明实验室![]() 浏览:156次
浏览:156次

近日,光明实验室未来智能互联网络团队的论文“MindDialog: A large-scale benchmark for counseling dialogue understanding and generation”成功被CCF B类期刊Pattern Recognition正式接收。该研究由光明实验室和深圳大学联合培养博士生胡赫,在崔来中教授的指导下完成。
MindDialog: A large-scale benchmark for counseling dialogue understanding and generation
He Hu, Juzheng Si, Qianning Wang, Tengjin Weng, Yihong Ji, Jiyue Jiang, Fei Ma, Yucheng Zhou, Laizhong Cui, Qi Tian
引言:AI开始“做心理咨询”,但它真的懂吗?
在心理健康需求持续增长的背景下,AI逐渐被用于情绪支持与心理咨询场景。它能够生成流畅、温和、甚至富有同理心的回应,这让很多人产生一种直观印象:AI似乎已经具备了“理解人类情绪”的能力。然而,问题也随之浮现——这些回应是否真正基于对心理状态的理解,还是仅仅来源于语言模式的模仿?
论文指出,当前主流评测方法主要关注表层表现,如情绪分类准确率或文本流畅性,却难以判断模型是否具备“心理推理能力”。换句话说,AI可以“说得像”,但不一定“理解对”。为了解决这一问题,MindDialog被提出,旨在构建一个更加贴近真实心理咨询场景的评测基准。
核心创新点:从真实数据到“可解释评测”
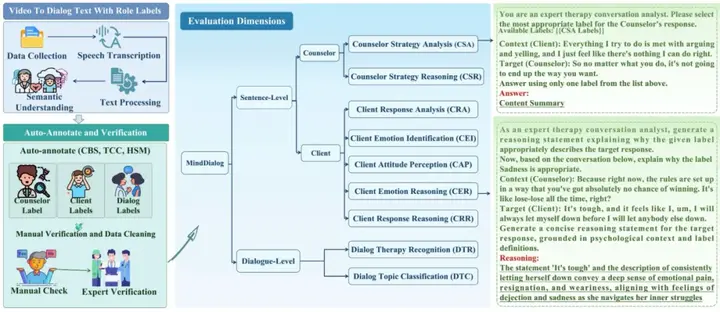
MindDialog的创新主要体现在两个方面:数据来源与评测方式。首先,在数据层面,该工作基于真实心理咨询视频构建数据集,而非依赖众包或合成对话。其整体流程如论文图1所示,从视频到对话文本,再到多维度评测任务,形成完整闭环
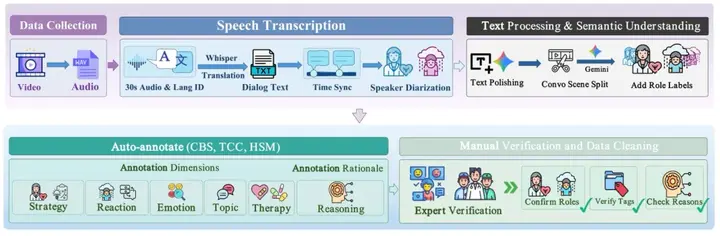
具体构建过程(见图2)涵盖语音转写、说话人识别、语义优化、多维标注以及专家审核,确保数据既具规模,又具专业性。这种基于真实场景的数据,使模型评测更具生态有效性。
其次,在评测设计上,MindDialog突破了传统“只做分类”的方式,引入了推理生成任务。模型不仅需要给出判断结果,还需要解释“为什么”。例如,不仅要判断某句话表达“悲伤”,还需要说明判断依据。这一设计将评测从“结果正确”提升到“推理合理”,能够有效区分模型是基于理解还是基于模式匹配。
实验结果:AI很强,但理解仍然停留在表层
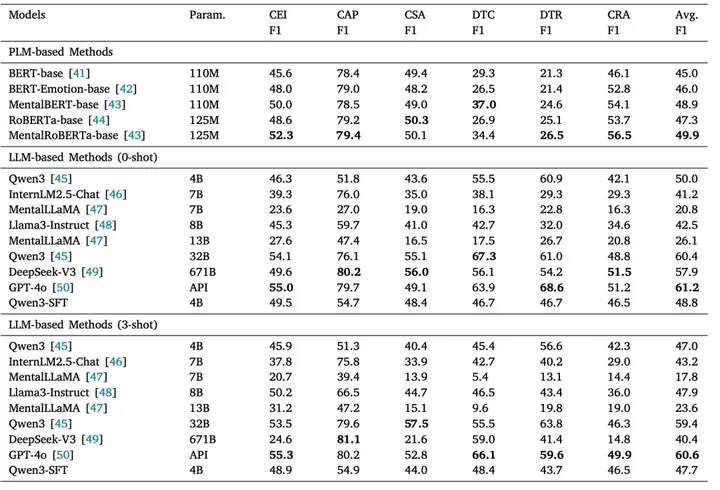
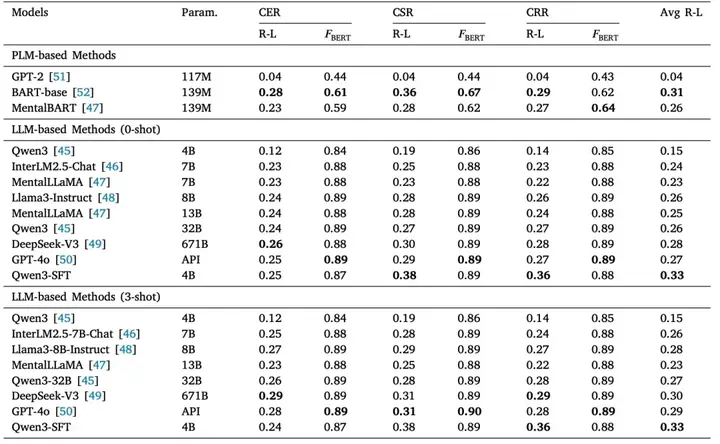
实验结果揭示了一个关键事实:当前大模型在表层任务上已经表现出色,但在深层理解上仍存在明显不足。 一方面,在情绪识别、策略分类等任务中,大模型能够取得较高准确率,说明其具备一定的语义理解能力;但另一方面,在推理解释任务中,即使是最先进的模型,也难以生成与专家一致的解释,表现为逻辑不充分、缺乏心理学依据,甚至出现误判。这表明模型在“解释为什么”这一关键能力上仍存在明显短板。更值得关注的是所揭示的现象:对强模型进行领域微调后,其性能反而下降。这一“微调悖论”说明模型并没有真正学习心理治疗知识,而是依赖已有的通用能力进行推断。一旦被限制在特定数据分布中,反而削弱了原有能力。这一结果进一步验证了一个重要结论:当前AI更多是在“模仿心理咨询”,而非“理解心理咨询”。
未来计划:从语言能力走向心理推理能力
MindDialog不仅揭示了问题,也为未来研究提供了明确方向。首先,评测体系需要进一步向“长期交互”扩展,引入多轮、多阶段的动态评估,以更真实地反映心理咨询过程;其次,应加强对风险识别与干预能力的评估,使模型能够在关键场景中做出安全、合理的决策;更重要的是,需要推动模型从“语言生成”走向“心理推理”,即能够基于理论框架进行判断和解释,而非简单依赖数据模式。论文指出,未来的关键在于构建具备临床合理性与可解释性的系统,使AI不仅能够表达共情,还能够理解其背后的心理机制,从而真正服务于心理健康领域。
论文链接:
https://www.sciencedirect.com/science/article/abs/pii/S0031320326007314
END
素 材 丨未来智能互联网络团队
编 辑 丨 李沛昱 曾小告
责 编 丨 陈贞儒
欢迎投稿、建议:gmlab@gml.ac.cn



 发布时间:2026-05-07
发布时间:2026-05-07 作者:光明实验室
作者:光明实验室 浏览:156次
浏览:156次